数据库索引
索引的原理
要理解索引原理必须清楚一种数据结构「平衡树」(非二叉),也就是b tree或者b+ tree,重要的事情说三遍:“平衡树,平衡树,平衡树”, 当然, 有的数据库也使用哈希桶作用索引的数据结构 , 然而, 主流的 RDBMS 都是把平衡树当做数据表默认的索引数据结构的
索引的直观感受
索引会提升查询数据库的速度,但是在访问量大,高并发的情况下,会导致写入数据时性能下降(其实是对数据的增删改都会变慢)
1、为什么要给表加上主键?
平时建表的时候都会为表加上主键, 在某些关系数据库中, 如果建表时不指定主键,数据库会拒绝建表的语句执行。
事实上, 一个加了主键的表,并不能被称之为「表」。
一个没加主键的表,它的数据无序的放置在磁盘存储器上,一行一行的排列的很整齐, 跟我认知中的「表」很接近。
这就是为什么一个表只能有一个主键, 一个表只能有一个「聚集索引」,因为主键的作用就是把「表」的数据格式转换成「索引(平衡树)」的格式放置。

建索引的缺点
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中。
2、为什么加索引后会使查询变快?
假如一张表有一亿条数据 ,需要查找其中某一条数据,按照常规逻辑, 一条一条的去匹配的话, 最坏的情况下需要匹配一亿次才能得到结果,用大 O 标记法就是 O(n)最坏时间复杂度,这是无法接受的,而且这一亿条数据显然不能一次性读入内存供程序使用, 因此, 这一亿次匹配在不经缓存优化的情况下就是一亿次 IO 开销,以现在磁盘的 IO 能力和 CPU 的运算能力, 有可能需要几个月才能得出结果 。如果把这张表转换成平衡树结构(一棵非常茂盛和节点非常多的树),假设这棵树有 10 层,那么只需要 10 次 IO 开销就能查找到所需要的数据, 速度以指数级别提升,用大 O 标记法就是 O(log n),n 是记录总树,底数是树的分叉数,结果就是树的层次数。换言之,查找次数是以树的分叉数为底,记录总数的对数,用公式来表示就是
用程序来表示就是 Math.Log(100000000,10),100000000 是记录数,10 是树的分叉数(真实环境下分叉数远不止 10), 结果就是查找次数,这里的结果从亿降到了个位数。因此,利用索引会使数据库查询有惊人的性能提升。
3、为什么加索引后会使写入、修改、删除变慢?
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间
索引能让数据库查询数据的速度上升, 而使写入数据的速度下降,原因很简单的, 因为平衡树这个结构必须一直维持在一个正确的状态, 增删改数据都会改变平衡树各节点中的索引数据内容,破坏树结构,
因此,在每次数据改变时, DBMS 必须去重新梳理树(索引)的结构以确保它的正确,这会带来不小的性能开销,也就是为什么索引会给查询以外的操作带来副作用的原因。
4、什么情况下要同时在两个字段上建索引?
待补充
5、聚集索引和非聚集索引?
「聚集索引」
如果给表上了主键,那么表在磁盘上的存储结构就由整齐排列的结构转变成了树状结构,也就是上面说的「平衡树」结构,换句话说,就是整个表就变成了一个索引。
没错, 再说一遍, 整个表变成了一个索引,也就是所谓的「聚集索引」。
「非聚集索引」
非聚集索引和聚集索引一样, 同样是采用平衡树作为索引的数据结构。索引树结构中各节点的值来自于表中的索引字段, 假如给 user 表的 name 字段加上索引 , 那么索引就是由 name 字段中的值构成,在数据改变时, DBMS 需要一直维护索引结构的正确性。如果给表中多个字段加上索引 , 那么就会出现多个独立的索引结构,每个索引(非聚集索引)互相之间不存在关联。

非聚集索引和聚集索引的区别
聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。 文章上面的内容已经指出, 当为字段建立索引以后, 字段中的内容会被同步到索引之中, 如果为一个索引指定两个字段, 那么这个两个字段的内容都会被同步至索引之中
索引的查询过程
1 | //建立索引create index index_birthday on user_info(birthday); |
这句 SQL 语句的执行过程如下首先,通过非聚集索引index_birthday查找birthday等于 1991-11-1 的所有记录的主键 ID 值然后,通过得到的主键 ID 值执行聚集索引查找,找到主键 ID 值对就的真实数据(数据行)存储的位置
最后, 从得到的真实数据中取得 user_name 字段的值返回, 也就是取得最终的结果我们把 birthday 字段上的索引改成双字段的覆盖索引
1 | create index index_birthday_and_user_name on user_info(birthday, user_name); |
这句 SQL 语句的执行过程就会变为
通过非聚集索引index_birthday_and_user_name查找birthday等于 1991-11-1 的叶节点的内容,然而, 叶节点中除了有 user_name 表主键 ID 的值以外, user_name 字段的值也在里面, 因此不需要通过主键 ID 值的查找数据行的真实所在, 直接取得叶节点中 user_name 的值返回即可。 通过这种覆盖索引直接查找的方式, 可以省略不使用覆盖索引查找的后面两个步骤, 大大的提高了查询性能,如下图!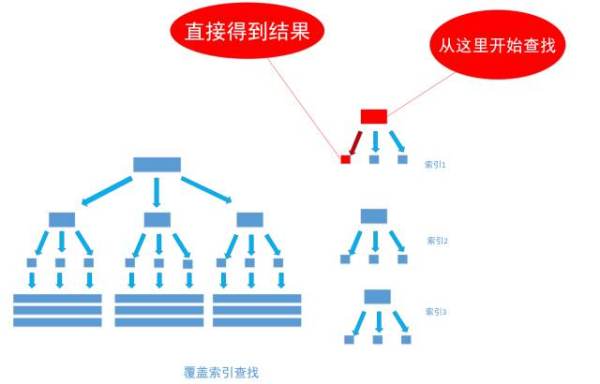
什么时候需要建索引
(来源于百度知道)
1、表的主键、外键必须有索引;
2、数据量超过 300 的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在 Where 子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以 AND 方式出现在 Where 子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在 Where 子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过 3 个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
以上是一些普遍的建立索引时的判断依据。
一言以蔽之,索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据。因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
总得来讲:当修改性能远远大于检索心梗时,不应该创建索引

